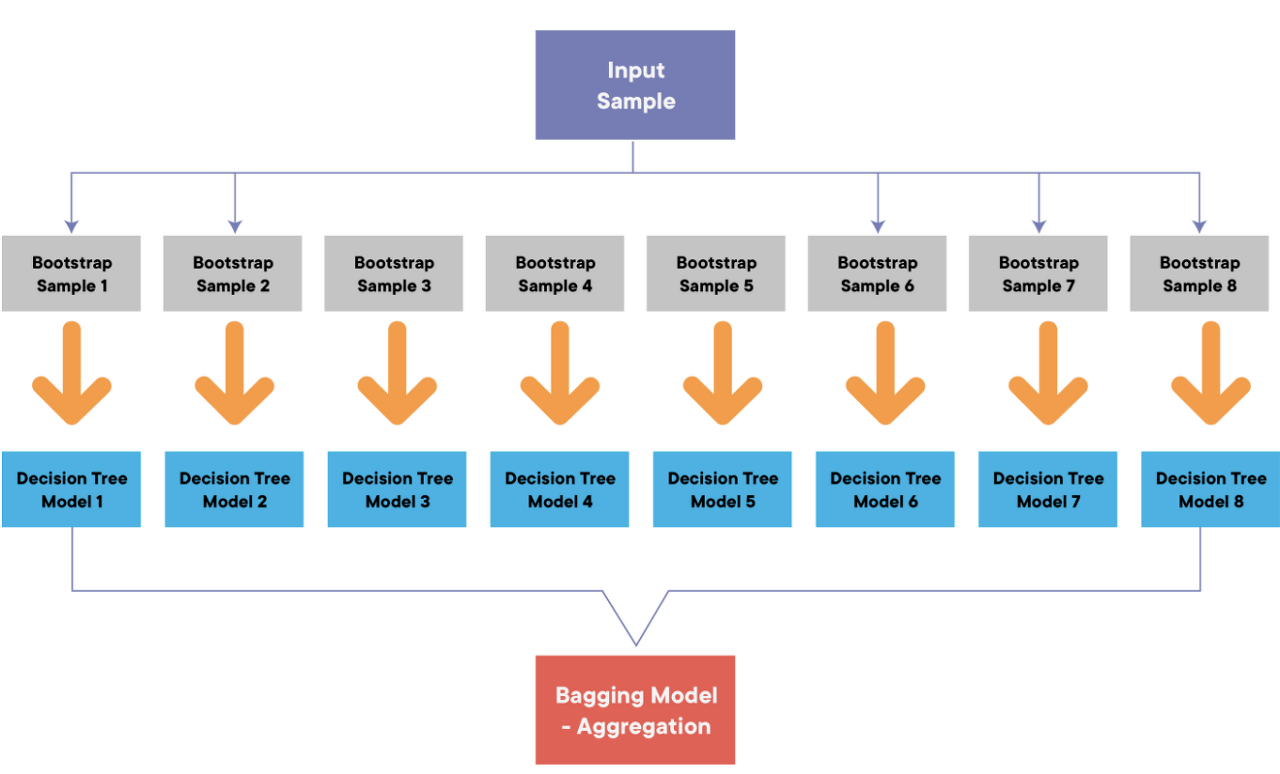
교차 검증 ( Cross-validation ) K-Fold 교차검증 교차검증은 데이터셋을 임의의 K개로 나누어, K개 중 1개는 테스트 셋으로 하고, 나머지 K-1개는 트레이닝셋으로 하여 학습하는 것을 말합니다. 이 때 테스트 셋을 K번 바꾸어 트레이닝과 테스트 셋을 교차하여 학습하는 방식입니다. 그래서 5개의 모델의 성능의 평균을 최종 성능으로 나타냅니다. Stratified K-FOLD 교차검증 그러면, 폴드 자체를 50대50으로 맞추는건지, 전체 데이터의 클래스 비율을 맞추는건지 예를 들어 5-Fold의 경우 위의 그림과 같이 학습이 진행되는 것입니다. 교차검증 with Python k = 5 # k-Fold ( K = 5 ) scores = cross_val_score(model, X_train..