단순선형회귀란
- 종속변수를 하나의 독립변수로 예측하는 것을 말합니다.
- 즉 기상청이 풍향 한가지로, 강수 확률을 예측하는 것과 같습니다. 왜 풍향만 보냐고 물어보실 수 있습니다.
- 단순선형이기 때문에 요인을 한가지만 보는 것입니다. 2개 이상의 요인을 고려하는 것은 다중선형회귀입니다. 다중선형은 다음에 블로깅하겠습니다.
단순 선형회귀의 구성

- B0과 B1은 회귀계수, ε은 오차항 이라고 한다.
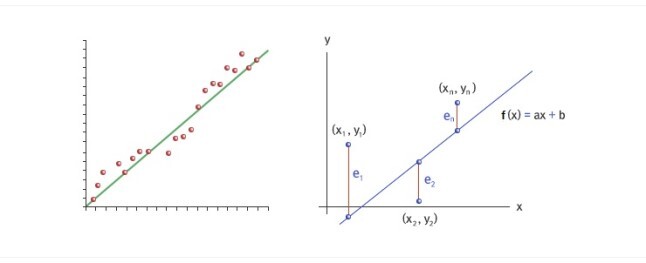
- 위 그림처럼, 회귀 직선은 잔차들의 제곱들의 합 RSS(Residual sum of squares)를 최소화 하는 직선을 나타냅니다.
- RSS는 SSE(Sum of Squares Error)라고도 말하며, 이 값이 회귀 모델의 비용함수(Cost Function)가 됩니다.
- 비용함수가 최소화 하는 모델을 찾는 과정을 학습이라고 말합니다.
추가로, 최소제곱법을 통한 B0과 B1은 회귀계수 추정은, B0과 B1을 각각 편미분하여, 얻은 식을 0으로 놓고 연립방정식
잔차 제곱합을 최소화하는 방법, 최소 제곱법( 최소 자승법 ), Ordinary least squares

- 전체 제곱합(SST) : 변인 값과 평균 사이의 편차를 제곱한 값들의 총합(SSR + SSE)
- 회귀 제곱합(SSR) : 예측값에서 평균을 뺀 수치를 제곱한 값들의 총합
- 잔차 제곱합(SSE) : 실제치와 추정치의 차이를 제곱한 값들의 합, 추정치로도 설명할 수 없는 차이를 말합니다.
- 결정계수 : 전체제곱합에서 회귀제곱합의 비율(SSR / SST),
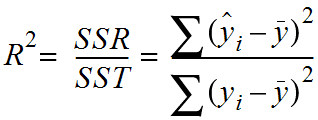
좋은 선형모델이란
- 선형회귀에서는 잔차제곱합을 최소화하는 방식으로 회귀계수를 추정합니다.
- 그래서 SSE 값이 작을 수록, 좋은 모델이라고 볼 수 있겠습니다
- 또한 결정계수가 1에 가까울 수록 데이터들이 회귀선 주위에 밀집되어 나타나게 되며 이는 회귀식이 타당하며 설명력이 높다고 볼 수 있습니다.
선형회귀모델의 장점
- 계수들에 대한 해석이 간단합니다.
선형회귀모델의 단점
- 통계분석의 목적이 예측 정확도일 경우, 좋은 결과를 도출하지는 않을 수도 있음
- 이상치에 민감하다
주의점
- 회귀 분석시 인과관계를 혼동하실 수 있습니다. 즉 회귀 계수가 1에 가깝더라도 해당 변수들이 연관이 있는 것이지, 원인이 되는 것이 아닙니다.
파이썬의 scikit-learn으로 단순회귀분석 해보기
예제 데이터 : https://www.kaggle.com/c/house-prices-advanced-regression-techniques/overview
House Prices - Advanced Regression Techniques | Kaggle
www.kaggle.com
공식 문서 : https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
sklearn.linear_model.LinearRegression — scikit-learn 0.24.2 documentation
scikit-learn.org
import pandas as pd
# 로컬파일 내 혹은 구글드라이브 등에 저장된 house prices 데이터를 가져옵니다.
df = pd.read_csv('파일경로/house-prices/house_prices_train.csv')
df_test = pd.read_csv('파일경로/house-prices/house_prices_test.csv')
feature = ['GrLivArea'] # 하나의 독립변수 설정(x1)
target = ['SalePrice'] # 종속변수 설정(x1)
X_train = df[feature]
y_train = df[target]from sklearn.linear_model import LinearRegression
model = LinearRegression() # 예측모델 인스턴스 생성
model.fit(X_train, y_train) # fit 메소드를 통해 모델 학습## 하나의 샘플을 선택해 학습한 모델을 통해 예측해보기
X_test = [[2000]]
y_pred = model.predict(X_test)
print(f'{X_test[0][0]} sqft GrLivArea를 가지는 주택의 예상 가격은 ${int(y_pred)} 입니다.')
[output]
2000 sqft GrLivArea를 가지는 주택의 예상 가격은 $237090 입니다.## 전체 테스트 데이터를 모델을 통해 예측해보기
X_test = [[x] for x in df_t['GrLivArea']]
y_pred = model.predict(X_test)print(y_pred)
[output]
array([[114557.82748987], [160945.27292207], [193084.38061182], ..., [149696.58523066], [122485.47405334], [232829.74378814]])## train 데이터에 대한 그래프를 그려보겠습니다.
plt.scatter(X_train, y_train, color='black', linewidth=1)
## test 데이터에 대한 예측을 파란색 점으로 나타내 보겠습니다.
plt.scatter(X_test, y_pred, color='blue', linewidth=1);

결론

- 오늘은 지도학습 중 비교적 간단한 머신러닝 기법에 속한 단순선형회귀을 공부했습니다.
- 단순선형회귀의 세부적인 예측 방법론적인 것도 중요했지만, 실제로 예측을 Python, R 등에서 할 때 전체적인 흐름은 위와 같다는 것도 잊으면 안될 것같습니다.
추가사항)
기준모델 ( Base line Model )
- 데이터의 기본적인 것을 통해 모델의 성능을 확인할 수 있는 모델 (ex. 평균으로 만든 모델)
- 최소한의 성능을 나타내는 기준이라고 볼 수 있다
- 이러한 기준 모델과 우리가 만든 모델을 비교하여, 최소한의 성능보다 높은지 체크할 수 있다.
- 분류 : Target의 최빈값
- 회귀: 타겟의 평균값
- 시계열회귀: 이전 타임스태프의 값
'머신러닝' 카테고리의 다른 글
| 원핫인코딩, 특성 선택, 릿지 회귀( Ridge Regression ) (0) | 2021.08.04 |
|---|---|
| 다중선형회귀( Multiple Linear Regression) (0) | 2021.08.03 |
| Clustering (0) | 2021.07.31 |
| High dimensional data, 차원 축소 (0) | 2021.07.31 |
| Feature Engineering, Data Manipulation (0) | 2021.07.15 |