모델해석
- 모델을 통해 결과를 해석하는 것은 분석 과정에서 매우 중요합니다. 이를 위해, 방법론적인 측면과 배경지식(도메인)이 중요합니다. 하지만 전문분야는 각기 다르기때문에 방법론적인 측면에서 해석하는 Python 라이브러리를 알아보고자 합니다.
PDP(부분의존도그래프)
- PDP(Partial Dependence Plot)란 예측모델을 만들었을 때, 어떤 특성(feature)이 예측모델의 타겟변수(Target variable)에 얼마나 영향을 주는지 알 수 있는 그래프입니다.
- PDP는 회귀와 분류 모두 사용가능합니다.
PDP with Python
from category_encoders import OrdinalEncoder
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv('분석하고자하는 데이터.csv')
target = '종속변수' # 예측, 분류 하고자하는 특성
features = df.columns.drop(target) # 종속변수를 제거한 나머지 특성
train, test = train_test_split(train, train_size=0.80, test_size=0.20,
stratify=train[target], random_state=42)
X_train = train[features]
y_train = train[target]
X_test = test[features]
y_test = test[target]
linear = make_pipeline(
OrdinalEncoder(),
LinearRegression()
)
linear.fit(X_train, y_train)
print('R-Square', linear.score(X_test, y_test))
import matplotlib.pyplot as plt
from pdpbox import pdp
feature = '원하는 특성 : weight '
features = '원하는 특성의 데이터 셋 모든 컬럼 : X_train.columns')
pdp_dist = pdp.pdp_isolate(model=linear,
dataset=X_test,
model_features=원하는 특성의 데이터 셋 모든 컬럼,
feature=원하는 특성)
pdp.pdp_plot(pdp_dist, feature);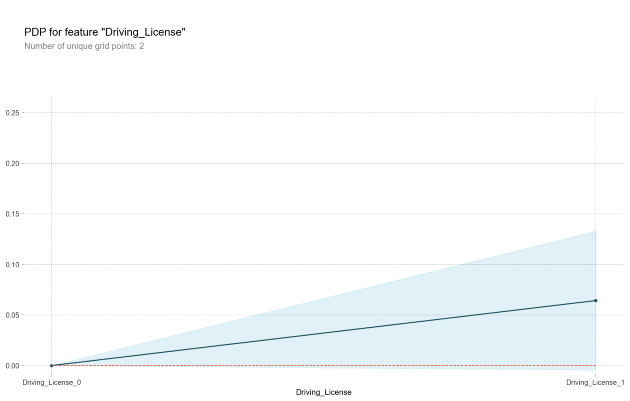
건강보험 가입자 데이터이며, 위의 그래프를 해석하자면, 운전면허가 있다면 자동차 보험에 가입하고 싶어할 확률이 높다고 해석할 수 있습니다.
PDP (2 특성 사용)
from pdpbox.pdp import pdp_interact, pdp_interact_plot
features = ['원하는 속성1', '원하는 속성2']
interaction = pdp_interact(
model=boosting,
dataset=X_test,
model_features=X_test.columns,
features=features
)
pdp_interact_plot(interaction, plot_type='grid',
feature_names=features);
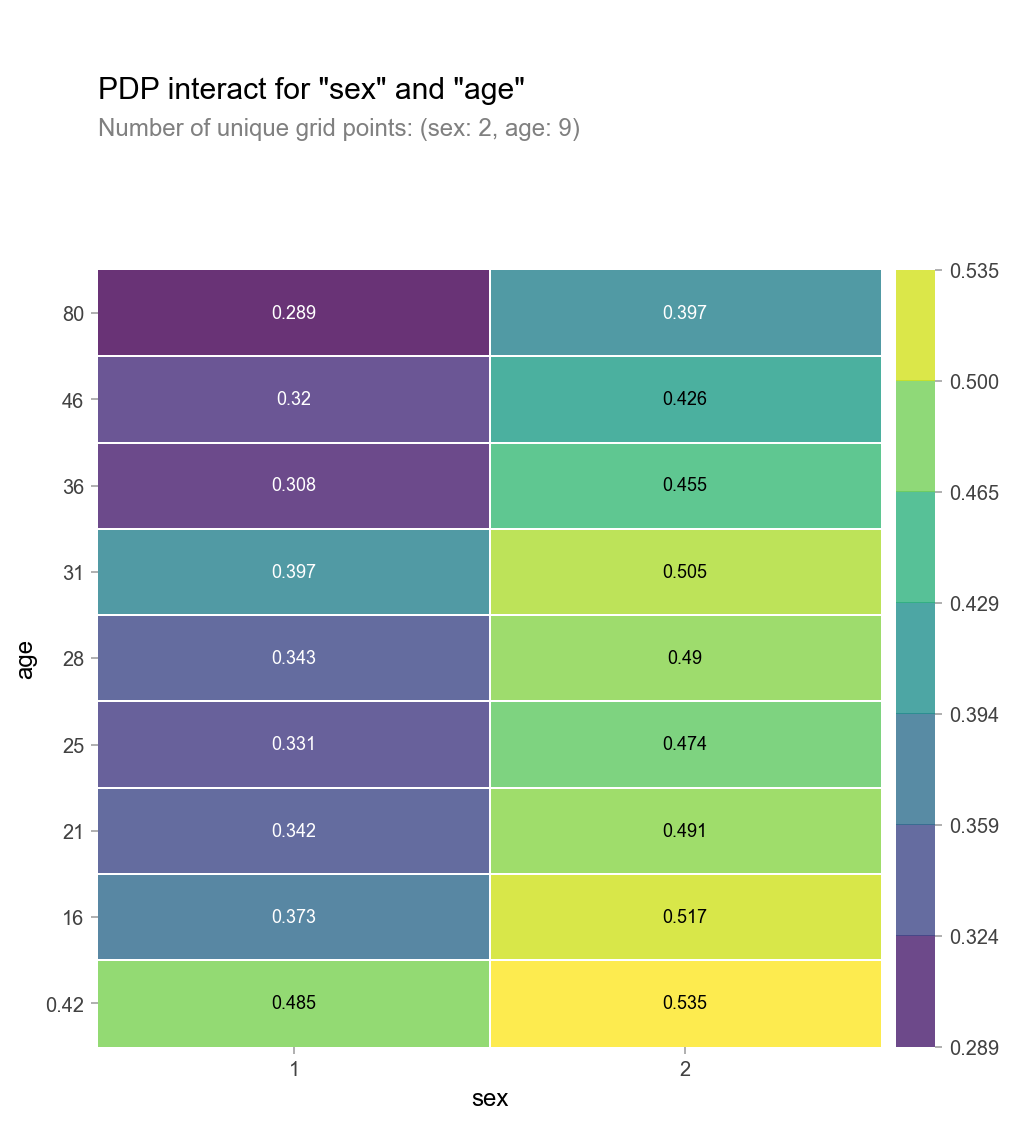
해당데이터는 타이타닉 데이터이며, 위의 그림은 해석하자면, sex=2 즉, 여자면서 나이가 어릴 수록 생존률이 높다고 해석할 수 있습니다.
SHAP
단일 관측치로부터 특성들의 기여도를 계산할 수 있는 라이브러리입니다.
아래 그림과 같이 특정 한사람의 데이터를 넣으면, 예측한 후 왜 그렇게 예측을 했는지 설명해주는 것입니다.
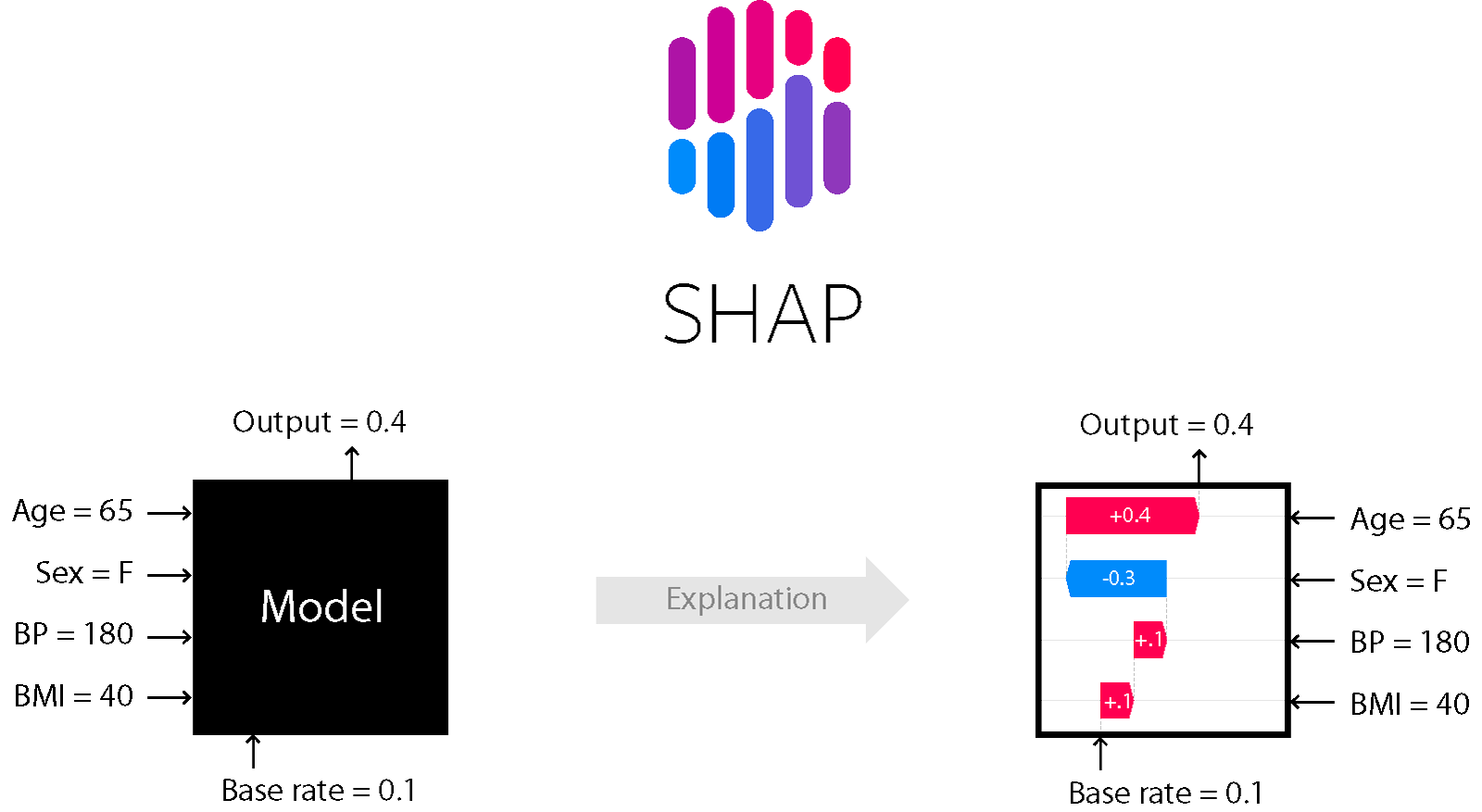
Shap with Python
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(알고 싶은 특정 하나의 데이터, 사람)
shap.initjs()
shap.force_plot(
base_value=explainer.expected_value[0],
shap_values=shap_values[0],
features=row
위의 코드와 아래 결과 그림을 보면, 해당 데이터는 가격을 예측하는 것이며 341,878.50원으로 예측하며 이 때 영향을 주는 특성을 살펴볼 수 있습니다.
'머신러닝' 카테고리의 다른 글
| 앙상블 기법과 속성 중요도 ( Feature Importances ) (0) | 2021.08.17 |
|---|---|
| 회귀, 분류 모델을 위한 데이터 변환 (0) | 2021.08.15 |
| 의사결정트리, 랜덤포레스트, 분류모델평가기법, 모델선택 복습 (0) | 2021.08.13 |
| 모델 선택( Model Selection ) (0) | 2021.08.12 |
| 분류모델 평가 기법 ( Evaluation Metrics for Classification ) (0) | 2021.08.11 |